Software Design & Engineering
Project Software Design and Engineering Enhancements
Project maintained by Arrioc Hosted on GitHub Pages — Theme by mattgraham
Sections
Self-Assessment | Introduction | Software Design & Engineering | Algorithms & Data Structures | Database | Old Source Code | New Source Code
Software Design & Engineering
My plan for software engineering and design is to improve the software by creating more readable output, more user-friendly input, and a well-rounded 'update' module for the API which will help to deliver better value. I will also remove unused code, improve commenting and try to fix any bugs.
-
Knowledge Acquisition
-
My MongoDB database demonstrates an understanding of how to import and manage a distributed database using appropriate MongoDB statements, tools, and techniques. It demonstrates my ability to manipulate the database with modules or Mongo shells and tune the database’s performance using indexes. This is an important skill to have because “NoSQL databases like MongoDB are emerging as the next big thing” (Sriparasa & D’mello, 2018, p. 136). This NoSQL database is fast, flexible, and scalable, and it provides tons of features that do not sacrifice speed (Chodorow, 2013, pp. 3-5).
-
Both the internal and API modules show that I understand how to connect to the database and carry out simple and complex functions using the appropriate JavaScript Object Notation (JSON), a widely popular data interchange format (Sriparasa & D’mello, 2018, p. 6). This is a critical skill to have because JSON is the go-to language for data interchange today (Sriparasa & D’mello, 2018, pp. 6-7). The internal and API modules show that I understand how apply CRUD functions for MongoDB database documents, perform queries and aggregations, test the code, find solutions to problems using branches and loops, and perform exception handling. The API modules show that I understand how to create and test uniform resource identifiers (URI's) and locators (URL’s), and implement the use of a basic RESTful web service using a language-specific web service framework like Bottle to rout paths and perform connections.
-
-
Developing Solutions
-
I met the planned objectives for creating more readable output, more user-friendly input, and a well-rounded update module for the API which helps to deliver better value. The artifact now has improved readability by integrating JSON code into specific inputs and outputs, for all modules that output data to the user. The artifact now has friendlier user input capability for all modules, by removing code that required the user to preformat their own inputs and injecting code that preformats the inputs for them using the JSON and Pymongo language. This allowed me to remove "bad formatting" error catch blocks. The API update module now better reflects the industry specific goal for update functionality by allowing the user to update any field in a specified document (not just the “volumes” field), or insert a new one, using the simple but effective solution of adding a variable to the CURL which is extracted and queried. I also added needed annotation comments to every module and fixed a bug for the API modules that calls the terminal again as it exits.
-
Better User Input:
Click to expand and view the code!
import json from bson import json_util from pymongo import MongoClient, errors from bson.json_util import dumps, loads connection = MongoClient('localhost', 27017) db = connection['market'] collection = db['stocks'] # This method returns 'false' and a message for when # document creation wasn't successful def update_document(query, newMod): try: myUpdateResult = collection.update_one(query, newMod) return myUpdateResult except errors.DuplicateKeyError as e: print("Duplicated key error", e) return False except WriteError as we: print("MongoDB returned error message", we) return False except WriteConcernError as wce: print("MongoDB returned error message", wce) return False except PyMongoError as pm: print("MongoDB returned error message", pm) abort(400, str(pm)) return # This method accepts input for a ticker. If the ticker doesnt # exist it exits, else it takes input for a key and value, and # preformats them. It then sends this data to the update # function.On return, it reports on whether the update worked. def modify_main(): #request ticker data for query print('Please enter capitolized Ticker name') #store variable for query newQuery = (raw_input()) #format user input myQuery = loads("{\"Ticker\" : \""+newQuery+"\"}") #check for document existance, exit if none if (not collection.find_one(myQuery)): print("Document not found.") #else continue... else: #store field input for modify_doc print('Please enter field name') key = (raw_input()) print('Please enter field value') value = (raw_input()) #check whether string or number, format accordingly if (value == int or float and not str): modify = loads("{\""+key+"\" : "+value+"}") else: modify = loads("{\""+key+"\" : \""+value+"\"}") newUpdate = {"$set" : modify} #update execution with query and modification myUpdateResult = update_document(myQuery, newUpdate) #if file was updated if (myUpdateResult.modified_count == 1): # print raw result & update results print(dumps(myUpdateResult.raw_result)) print("Document updated!") #if file is not updated else: #print raw result & update result print(dumps(myUpdateResult.raw_result)) print("File was not modified, possibly because the modification already exists.") modify_main() -
User Input Before Enhancement:
-

-
User Input After Enhancement:
-

-
Database Document Segment Before Changes:
-

-
Database Document Segment After Changes (Note Modified Key & New Key):
-

-
Better Readability:
Click to expand and view the code!
import json from bson import json_util from pymongo import MongoClient, errors from bson.json_util import dumps from bottle import get, route, run, request, abort connection = MongoClient('localhost', 27017) db = connection['market'] collection = db['stocks'] # This method executes the aggregation pipeline, then reports # a portfolio on the top five shares with the given aggregation # criteria. #aggregate Function def aggregate(aggreg): try: myReadResult = collection.aggregate(aggreg) print(myReadResult) #if aggregation does not equal 'None' if (myReadResult != None): #convert to json and print print("Top five shares grouped by company, strength, 200-Day SMA.") print(dumps(myReadResult, indent=4, default=json_util.default)) return except Exception as pm: print(dumps("MongoDB returned error message", pm)) # This method extracts the CURLS's industry and sets up an # aggregation pipeline with it. The aggregation matches the industry # and groups the top companies by thier relative strength index and # the highest 200-Day SMA. It then sorts them by their highest strength # index. The method first reports an error if the industry doesnt exist, # it then sends the aggregation to the 'aggregation' function. #URI for REST service @get('/stocks/api/v1.0/industryReport') def main_aggregate_API(): #take value for query industry = request.json["Industry"] #aggregation filtering & projection criteria aggregationQ = [{"$match" : {"Industry" : {"$regex" : ".*"+industry+".*"}}}, {"$sort" : {"HighestStrength" : -1}}, {"$group" : {"_id" : "$Company", "HighestStrength" : {"$max" : "$Relative Strength Index (14)"},"Highest200-DaySMA" : {"$max" : "$200-Day Simple Moving Average"}}}, {"$limit" : 5}] #if industry query doesnt exist, print error match = {"Industry" : {"$regex" : ".*"+industry+".*"}} if (collection.find(match).count() == 0): print("No Matches Found For:") print(dumps(match)) #else send variables to aggregation function else: myReadResult = aggregate(aggregationQ) if __name__ == '__main__': run(host='localhost', port=8080, debug=True) -
Readability Before:
-

-
Readability After:
-

-
Improved API Update:
Click to expand and view the code!
import json from bson import json_util from bson.json_util import dumps from pymongo import MongoClient, errors from bottle import get, put, route, run, request, abort connection = MongoClient('localhost', 27017) db = connection['market'] collection = db['stocks'] # This method executes the update and returns results to # the main program. If they ticker was modified, and the # new ticker already exists, duplicate key error is reported. #update funtion def update_document(query, newMod): try: myUpdateResult = collection.update_one(query, newMod) return myUpdateResult except errors.DuplicateKeyError as e: print("Duplicated key error", e) return False except errors.PyMongoError as pm: print("MongoDB returned error message", pm) abort(400, str(pm)) return # This method takes a ticker and key from the users CURL. # It uses the ticker as the query parameter, and sets the # key's value (which is a key and value) as the update parameter # and calls 'update_function'. Upon return, the result is checked # and reports whether the document was updated, has already been # modified, or is not found. #URI paths for REST service @put('/stocks/api/v1.0/updateStock') def main_update_API(): #get ticker ticker = request.params.get('ticker') myQuery = {"Ticker" : ticker} #check for document existance, exit if none if (not collection.find_one(myQuery)): print("Document not found.") #else continue... else: #get key & value in json modify = request.json["key-value"] #set key and value to update newUpdate = {"$set" : modify} #pass query and update to update function myUpdateResult = update_document(myQuery, newUpdate) #if file was modified if (myUpdateResult.modified_count == 1): #print raw result & update result print(dumps(myUpdateResult.raw_result)) print("Document updated!") #if file was not modified else: #print raw result & update result print(dumps(myUpdateResult.raw_result)) print("File was not modified. The modification already exists.") if __name__ == '__main__': run(host='localhost', port=8080, debug=True) -
API Update Module Code - Hard-Coded:
-

-
API Update Module Code - Not Hard-Coded:
-
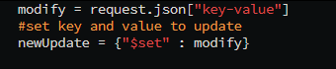
-
Database Document Before CURL:
-

-
Client Side URL (CURL) Request For API Update:
-

-
Database Document After CURL:
-

-
Bug & Structure Fixes:
-
Bug Exit Problem Before - API Modules Call Twice on Exit:
-

-
Bug Exit Problem After - Exits Properly:
-

-
Bug Culprit (call on Exit Fixed by Removing This):
-

-
Structure Issue Before - Program Not Exiting After Bad Entry:
-

-
Structure Issue After - Solved by Restructuring Code:
-

-
Structure Fix - Nesting With if/else:
-

-
-
Reflecting on the Process
-
As I worked to improve the API’s update program to accept any user field, after many failures, I began examining other examples of ways in which CURLS can be made. By observing in the “stockReport” module that I was able to take a key variable “array” to input its value, an idea occurred to me. I could simply create a new “key” variable for the CURL whose value would be the embedded key and value which I wanted to extract. I applied the idea to the module, and it worked.
-
As I worked to remove user formatting issues such as having the user input data in JSON or with quotes, I was faced with the challenge of needing to know exactly what the JSON utility, “loads”, and “dumps” were doing to the input code. I researched “loads” and “dumps” to refresh my memory and found a great site that explains specifically what they do. Loads turns strings into JSON objects, and dumps turns JSON objects into strings (Educative, Inc., 2021). Understanding “loads” and “dumps” allowed me format input for the user, simplifying their tasks. This understanding also helped me with my next task, fixing output readability.
-
I almost gave up creating more readable output because sites like StackOverflow repeatedly said it was not possible (StackOverflow, 2015). Help-site opinions are not always accurate. Sometimes it helps to ignore opinions and dive deeper. For me, it helped to study an old exercise (a “timestamp” module) whose output to the terminal looked ideal. The code used “loads” before printing, and then use “dumps” along with some commands inside the print statement. Inside the print parentheses, after the string or variable to print, one can write “indent=4, default=json_util.default.” This indents the data, making it more exposed and orderly. I then applied this knowledge to every module that outputs data, including the API (for future developers). I then made a post about my discovery to StackOverflow, for future questioners like myself. Since then, someone edited it to look nicer using color coding and highlighting, which I was surprised to see.
-
Next is Algorithms & Data Structures
-
-
References
-
Chodorow, K. (2013). Mongo DB: The definitive guide (2nd ed.). O’Reilly Media, Inc. https://www.oreilly.com/library/view/mongodb-the-definitive/9781449344795/
-
Educative, Inc. (2021). What is the difference between json.loads() and json.dumps()? https://www.educative.io/edpresso/what-is-the-difference-between-jsonloads-and-jsondumps
-
Sriparasa, S., & D’mello, B. (2018). JavaScript and JSON essentials : Build light weight, scalable, and faster web applications with the power of JSON (2nd ed.). Packt Publishing. https://search-ebscohost-com.ezproxy.snhu.edu/login.aspx?direct=true&db=nlebk&AN=1801025&site=eds-live&scope=site
-
StackOverflow. (2015, December 28). Pretty printing of output in Pymongo. Retrieved May 22, 2021, from https://stackoverflow.com/questions/34493535/pretty-printing-of-output-in-pymongo